Оптимизация приложений С++Builder в архитектуре клиент/сервер
Наталия ЕлмановаОдним из главных факторов, влияющих на принятие решения о переносе информационных систем в архитектуру клиент/сервер, является потенциальная возможность повышения производительности работы пользователей, особенно в тех случаях, когда находящиеся в эксплуатации приложения не удовлетворяют требованиям, предъявляемым к скорости обработки данных ввиду их большого объема, а также высокой интенсивности и сложности запросов. Известно, что информационные системы, основанные на архитектуре клиент/сервер, могут обладать существенными преимуществами перед информационными системами, базирующимися на сетевых версиях настольных СУБД, такими, как существенно меньший сетевой трафик, меньшее время обработки запросов, меньшая ресурсоемкость клиентских приложений и меньшие трудозатраты при их разработке.
Однако сам по себе факт переноса имеющейся базы данных из настольной СУБД на какой-либо сервер баз данных с соответствующей корректировкой настроек BDE (или других средств доступа к данным) отнюдь не гарантирует повышения производительности информационной системы в целом. Представьте себе, например, базу данных, содержащую одну-единственную таблицу из сотни записей и пяти целочисленных полей, содержащуюся в Oracle Workgroup Server, функционирующем под управлением Windows NT на персональном компьютере с 16 Мб оперативной памяти, и однопользовательское приложение, использующее навигационные методы для ее редактирования. В этом случае, безусловно, проще хранить данные в таблице формата dBase или Paradox — производительность системы будет в этом случае, скорее всего, намного выше, так как такой сервер, как Oracle, требует сам по себе немало ресурсов, а объем обрабатываемых данных и технология их обработки не оправдывают затрат, связанных с приобретением, установкой и эксплуатацией серверной СУБД такого класса. Данный пример, конечно, несколько утрирует реальную ситуацию, но иногда на практике происходят и более экзотические случаи…
Итак, какие шаги нужно предпринять для того, чтобы действительно повысить эффективность работы пользователей и производительность системы в целом? Первым шагом в данном направлении является, конечно, выбор сервера. В этом случае, к сожалению, нельзя давать однозначных рекомендаций типа "возьмите Oracle, он надежен" или "возьмите IB, он недорого стоит". Выбор сервера, управляющей им операционной системы и соответствующего аппаратного обеспечения должен осуществляться с учетом реальных и потенциально ожидаемых условий эксплуатации системы, таких, как скорость роста объема данных (например, в мегабайтах в месяц), интенсивность транзакций, вероятность многопользовательского доступа к одной или соседним записям в таблицах (при высокой вероятности желательно выбрать сервер, при использовании которого можно избежать страничных блокировок), потенциальный рост интенсивности работы пользователей, наличие повышенных требований к безопасности и защите данных (некоторые серверные СУБД выпускаются в разных исполнениях, отличающихся друг от друга степенью защищенности данных), необходимость использования продуктов сторонних производителей (таких, как ODBC-драйверы, дополнительные библиотеки и утилиты и др.), наличие связанных с этим проблем (типичным примером из недавней реальной практики была, например, проблема поиска ODBC-драйвера к серверу Centura SQLBase 6.0, поддерживающего использование хранимых процедур). Не менее, чем технические, важны и финансовые аспекты этой проблемы. Планируется ли использовать для установки серверной СУБД уже имеющеся вычислительные мощности и операционную систему или следует приобрести новые? В какую сумму обойдется приобретение серверной СУБД, клиентских лицензий, аппаратного обеспечения? Сколько будет стоить администрирование этой СУБД и управляющей ей операционной системы, а также обучение будущих администраторов и программистов? Сколько подключений к серверу допускается при приобретении одной лицензии — одно, два, четыре? Каковы условия, налагаемые лицензионными соглашениями при использовании мультиплексирования соединений за счет эксплуатации серверов приложений, если в дальнейшем возможен переход к трехзвенной архитектуре? Принятие решения о выборе серверной СУБД существенно зависит от ответа на все эти вопросы, и не всегда технические аспекты или мнение разработчиков определяют в конечном итоге выбор сервера. Нередки также случаи, когда предполагается использование уже имеющейся в наличии серверной СУБД (или даже готовой базы данных).
Предположим, что сервер выбран (исходя из вышеизложенных или каких-либо иных соображений). Каким образом следует использовать предоставляемые им возможности? Эффективность эксплуатации информационной системы с точки зрения производительности зависит от согласованной работы трех ее составных частей — сервера баз данных, клиентского приложения и клиентской части серверной СУБД, функционирующих на рабочей станции, и сети, и неоптимальная работа одной из этих частей может свести к нулю результат всех усилий, направленных на оптимизацию работы остальных частей. Таким образом, проблема оптимизации работы информационной системы достигается путем решения нескольких задач: оптимизации клиентской части, оптимизации серверной части, снижения сетевого трафика. Ниже мы рассмотрим некоторые приемы, способствующие в той или иной степени решению этих задач. Однако перед этим изучим один из простейших способов контроля содержимого запросов, пересылаемых на сервер баз данных библиотекой BDE, и результатов их выполнения, с помощью утилиты SQL Monitor, входящей в комплект поставки С++Builder.
Контроль запросов с помощью SQL Monitor.
SQL Monitor используется для контроля запросов, пересылаемых клиентским приложением серверу баз данных посредством BDE, и их результатов, а также измерения времени между ними. Для его запуска следует выбрать пункт SQL Monitor из меню Database C++Builder. Главное окно SQL Monitor состоит из двух частей. В верхней части отображаются последовательно генерируемые SQL-предложения и сведения об откликах сервера, а также порядковый номер и время их наступления, а в нижней части — полный текст SQL-запроса. Список, отображаемый в верхнем окне, можно сохранить в файле для дальнейшего анализа. На рис.1 представлен типичный вывод сведений при работе приложения, рассмотренного в предыдущей статье данного цикла.
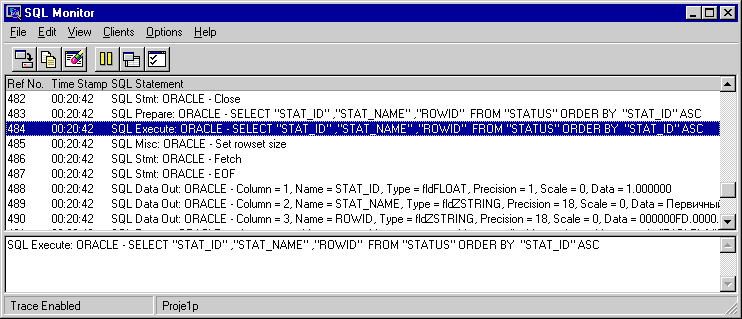
Рис.1. Вывод сведений о выполнении сервером запросов в SQL Monitor
При использовании SQL Monitor возможен выбор типов отображаемых сведений. Их можно выбрать в диалоге Trace Options, вызываемом из меню Options.
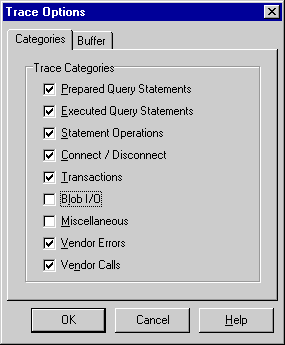
Рис.2. Диалог Trace Options для выбора действий, отображаемых в SQL Monitor
SQL Monitor позволяет отображать сведения о следующих действиях:
- Prepared Query Statements — SQL-предложения, передаваемые на сервер
- Executed Query Statements — SQL-предложения, готовые к выполнению сервером
- Statement Operations — действия, выполняемые сервером (FETCH, EXECUTE и др.)
- Connect/Disconnect — действия, связанные с установкой или разрывом соединения с сервером.
- Transactions — действия, связанные с выполнением транзакций (BEGIN, COMMIT, ROLLBACK)
- Blob I/O — действия, связанные с передачей Blob-полей
- Miscellaneous — другие действия
- Vendor Errors — сообщения об ошибках, возвращаемые сервером
- Vendor Calls — вызовы функций API клиентской части, связанных с обращением к серверу
Использование SQL Monitor является простейшим (хотя и не единственным) средством тестирования производительности информационных систем в архитектуре клиент/сервер, и эффективность применения большинства рассматриваемых ниже приемов их оптимизации можно проконтролировать с его помощью.
Минимизация обращений к серверу и сети
Минимизация связей с сервером влияет на производительность всех составных частей информационной системы — клиента, сервера и сети. Лишние связи с сервером приводят к созданию дополнительных объектов (таких, как TDatabase) в клиентском приложении, генерации дополнительных запросов к серверу для выяснения прав пользователя на доступ к тем или иным объектам базы данных, а также к непроизводительному использованию ресурсов сервера. Для минимизации связей с сервером можно использовать такие приемы, как использование в явном виде компонента TDatabase вместо неявного их создания, использование кэширования данных и структуры, хранение сведений о метаданных в клиентском приложении, использование локальных фильтров и др.
Использование компонента TDatabase
При использовании нескольких компонентов TDataSet следует иметь в виду, что каждый из них стремится во время выполнения создать неявно свой объект TDatabase для связи с сервером. Если же поместить компонент TDatabase на форму или в модуль данных на этапе проектирования приложения, и связать с ним все компоненты TDataSet, указав его имя в качестве значения свойства DatabaseName этих компонентов, все они будут использовать одну общую связь, обеспеченную этим компонентом.
Использование параметра SQLPASSTHRU MODE
Еще один способ минимизации связей с сервером заключается в изменении значения параметра SQLPASSTHRU MODE компонента TDatabase (либо псевдонима, созданного утилитой конфигурации BDE). Этот параметр определяет, могут ли использоваться общие соединения с базой данных запросами, сгенерированными приложением (например, с помощью компонента TQuery), и запросами, сгенерированными самой библиотекой BDE (например, при реализации навигационных методов компонента TTable). Значением этого параметра по умолчанию является NOT SHARED, позволяющее избежать возможных конфликтов при многопользовательском обновлении данных, но создающее отдельные соединения с базой данных для обоих типов запросов.
Наиболее эффективным с точки зрения минимизации соединений с базой данных значением этого параметра в большинстве случаев является значение SHARED AUTOCOMMIT. При использовании этого значения изменения каждой записи в таблицах немедленно фиксируются сервером независимо от типа вызвавшего их запроса, но при этом оба типа запросов могут использовать одно и то же соединение с базой данных. Этот режим наиболее близок к режиму, в котором используются сетевые версии настольных СУБД. Однако так как сервер в этом случае должен немедленно фиксировать результаты изменения записей, он инициирует и завершает отдельную транзакцию при изменении каждой записи, что может привести к перегрузке сервера и сети и к снижению производительности вместо ожидаемого ее повышения. Поэтому эффективность использования такого режима должна быть обязательно проверена путем тестирования.
Третье возможное значение этого параметра — SHARED NOAUTOCOMMIT. В этом случае оба типа запросов могут также использовать одно и то же соединение с базой данных, причем без завершения транзакций после редактирования каждой записи. Однако в этом случае контроль за завершением транзакций следует осуществлять в клиентском приложении. Подобный режим может быть весьма эффективен, так как перегружающие сервер транзакции автоматически не инициируются после редактирования каждой записи, но при его использовании могут возникать конфликты и непредсказуемые изменения данных при попытке одновременного редактирования одной и той же записи разными пользователями. Поэтому данный режим следует использовать только в том случае, если вероятность подобных коллизий мала.
Кэширование метаданных на рабочей станции
Еще один способ минимизации связей с сервером заключается
в использовании кэширования структуры таблиц на рабочей станции. В этом
случае снижается число обращений к серверу с целью определения метаданных,
т.е. количества столбцов в используемых в приложении таблицах, их имен
и типов данных. Для этой цели используются следующие параметры псевдонима
базы данных (или компонента TDatabase):
ENABLE SCHEMA CACHE — разрешено ли кэширование метаданных;
SCHEMA CACHE SIZE — количество таблиц, структура которых кэшируется;
SCHEMA CACHE TIME — время хранения информации в кэше в секундах; значение
-1 соответствует времени хранения данных в кэше до закрытия приложения;
SCHEMA CACHE DIR — каталог для кэширования метаданных.
Применение кэширования метаданных может существенно повысить производительность клиентских приложений и снизить нагрузку на сеть. Однако применять его можно только в том случае, если структура таблиц не меняется в течение работы приложения. Если же в процессе работы приложения производится добавление или удаление столбцов, создание или удаление индексов (не обязательно этим же приложением), создание и удаление временных таблиц, информация в кэше может оказаться не соответствующей действительности, что может привести к ошибкам, связанным с недопустимыми типами данных, недопустимыми преобразованиями типов и др. В этом случае применять кэширование метаданных не рекомендуется.
Использование потомков TField в клиентском приложении
Другим способом хранения на рабочей станции приложении сведений о метаданных является использование компонентов — потомков TField. Так как соответствующие объекты хранят сведения о структуре таблиц непосредственно в приложении, на этапе выполнения не производится обращений на сервер с целью получения метаданных. Использование потомков TField предпочтительнее, чем использование методов FieldByName() или свойства Fields, так как последние используют обращение к серверу для получения сведений о типах полей. Ограничения на применение компонентов — потомков TField такие же, как и в предыдущем случае — их использование рекомендуется при стабильной структуре таблиц. Помимо этого, изменение структуры данных на сервере может потребовать модификации приложения и, как следствие, установку его новой версии на рабочие станции.
Кэширование данных на рабочей станции
Помимо кэширования метаданных нередко применяется и кэширование на рабочей станции самих данных. Для этой цели следует установить равным true значение свойства CachedUpdates соответствующего компонента TDataSet. В этом случае все внесенные пользователем изменения сохраняются в локальном кэше. Сохранение данных на сервере производится с помощью метода ApplyUpdates() компонента TDataSet, а метод CommitUpdates() очищает кэш. В целом такой метод снижает сетевой трафик и суммарное число соединений с сервером, так как, во-первых, при редактировании данных в кэше не требуется наличия соединения с сервером, а во-вторых, сохранение нескольких записей из кэша на сервере может быть осуществлено путем выполнения одной-единственной транзакции. Помимо этого, снижается суммарное число блокировок записей на сервере, так как в процессе редактирования данных в кэше необходимости в блокировках нет.
Использование локальных фильтров при небольших объемах данных
Если компонент TDataSet доставляет на рабочую станцию небольшой по объему набор данных, сравнимый с размером кэша рабочей станции (определяемого параметрами MINBUFSIZE и MAXBUFSIZE системных настроек BDE), он будет полностью кэшироваться на рабочей станции. В этом случае применение локальных фильтров более предпочтительно, чем использование запросов с предложением WHERE, направляемых на сервер, так как в первом случае не требуется обращение к серверу.
Оптимизация использования сервера
Использование хранимых процедур
При выполнении многократно повторяющихся действий, использующих данные с сервера (например, при статистической обработке содержащихся в таблицах данных) производительность информационной системы можно повысить, используя хранимые процедуры сервера вместо SQL-запросов, генерируемых клиентским приложением. Дело в том, что переданный из клиентского приложения SQL-запрос сервером оптимизируется, компилируется и лишь затем выполняется, а хранимые процедуры сервера уже содержатся в оптимизированном и скомпилированном виде, поэтому обработка данных с их использованием требует меньших затрат времени, особенно при небольшом числе и суммарном объеме передаваемых параметров процедуры.
Однако следует иметь в виду, что хранимые процедуры пишутся на процедурном расширении SQL используемого сервера. Cуществуют официальные стандарты непроцедурного языка SQL ANSI/ISO SQL-86, SQL-89 и SQL-92, но на сегодняшний день не существует стандартов на процедурные расширения этого языка. Каждая серверная СУБД имеет свой набор процедурных расширений, отличающийся от соответствующих расширений других СУБД. Некоторые сервера, например Borland IB Database, поддерживают создание и использование в процедурах функций, определенных пользователем (UDF — User Defined Functions), а некоторые не поддерживают. Поэтому при смене платформы хранимые процедуры, скорее всего, потребуется переписывать. Отметим также, что чаще всего серверные хранимые процедуры создаются путем ручного кодирования, и для их создания, как правило, не существует удобных визуальных средств разработки и отладки наподобие имеющихся в C++Builder. Поэтому при принятии решения о создании тех или иных хранимых процедур не мешает оценить возможные трудозатраты — иногда может оказаться, что они не стоят ожидаемого эффекта.
Если же хранимые процедуры применяются активно, еще большего повышения производительности при их использовании можно достичь, минимизируя число и объем передаваемых на сервер параметров. Очевидно, что передать на сервер целое число намного проще, чем переслать длинную символьную строку, поэтому при планировании хранимых процедур с подобными параметрами есть смысл подумать о перепроектировании базы данных и создании, например, таблиц-справочников либо, при небольших объемах таких таблиц, о хранении их на рабочей станции или организации соответствующих массивов.
Использование предварительной подготовки запросов
При использовании компонентов TQuery нередко бывает полезно использовать метод Prepare(), особенно если компонент TQuery содержит параметризованный запрос. Метод Prepare() осуществляет пересылку запроса на сервер, где он оптимизируется и компилируется, а при открытии запроса на сервер в этом случае посылаются только его параметры. Особенно заметным повышение производительности может оказаться тогда, когда параметризованные запросы с различными значениями параметров повторяются часто — в этом случае повторная подготовка запроса не потребуется. Если же метод Prepare() не вызывается явно, он будет автоматически вызываться неявно каждый раз при пересылке параметров, инициируя пересылку всего текста запроса на сервер.
Что каcается передаваемых на сервер параметров запроса, их число и объем рекомендуется минимизировать точно так же, как и в случае параметров хранимых процедур.
Использование представлений (View) и параметризованных запросов.
Нередко начинающие программисты используют динамическое создание запросов на этапе выполнения, изменяя содержимое строкового массива, содержащегося в свойстве SQL компонента TQuery (например, периодически модифицируя предложение WHERE). При часто повторяющихся запросах такого типа это не самый оптимальный способ пересылки запросов на сервер, так как в этом случае обязательно осуществляется предварительная подготовка запросов, заключающаяся в пересылке всего текста на сервер, а также оптимизации и компиляции его сервером. Более предпочтительным в этом случае является использование параметризованных запросов и метода Prepare(), либо использование представлений (View) сервера, представляющих собой не что иное как хранимый на сервере заранее скомпилированный запрос. В последнем случае можно избежать не только лишних повторных компиляций запроса сервером, но и излишней перегрузки клиента генерацией запросов.
Использование свойства UpdateMode
Свойство UpdateMode компонентов TDBDataSet определяет состав оператора WHERE, генерируемого BDE при обновлении данных. Рассмотрим, каким получится оператор WHERE при редактировании поля SYMBOL содержащейся на сервере Oracle Workgroup Server копии таблицы HOLDINGS из входящей в комплект поставки C++Builder базы данных BCDEMOS при разных значениях этого свойства. Сгенерированные SQL-предложения можно пронаблюдать с помощью SQL Monitor.
По умолчанию значением свойства UpdateMode является UpWhereAll, и в этом случае BDE генерирует предложение WHERE, содержащее все поля таблицы. При этом сгенерированный оператор SQL, если только он не переопределен с помощью компонента TUpdateSQL, будет выглядеть следующим образом:
UPDATE "HOLDINGS" SET "SYMBOL"=:1 WHERE "ACCT_NBR"=:2 AND "SYMBOL"=:3 AND "SHARES"=:4 AND "PUR_PRICE"=:5 AND "PUR_DATE"=:6 AND "ROWID"=:7.
Этот способ определения изменяемых строк таблицы является самым медленным (особенно в случае таблиц с большим числом полей), но и наиболее надежным, так как практически гарантирует достоверную идентификацию записи в любой ситуации, даже в случае отсутствия ключевых полей (если, конечно, таблица удовлетворяет требованию реляционной модели, гласящему, что каждая запись должна быть уникальна и, следовательно, должна обладать уникальным набором полей).
Одним из других возможных значений этого свойства является UpWhereChanged, при котором в предложении WHERE содержатся только поля, измененные в данном запросе, и ключевые поля. В этом случае запрос имеет следующий вид:
UPDATE "HOLDINGS" SET "SYMBOL"=:1 WHERE "ROWID"=:2 AND "SYMBOL"=:3
Такой запрос выполняется быстрее, но в этом случае возможны коллизии при многопользовательской работе. Например, один пользователь считывает запись для редактирования в клиентское приложение, другой сразу после этого ее удаляет, а третий создает новую с теми же значениями изменяемых полей и теми же значениями ключевых полей. Именно эта новая запись и будет модифицироваться вместо считанной. Однако такой случай маловероятен, особенно если ставшие ненужными первичные ключи удаленных записей какое-то время не используются (например, при создании ключей с помощью генераторов последовательностей).
Третьим возможным значением свойства UpdateMode является UpWhereKeyOnly. В этом случае предложение WHERE содержит только ключевое поле:
UPDATE "HOLDINGS" SET "SYMBOL"=:1 WHERE "ROWID"=:2
Хотя это самый быстрый способ обновления данных по сравнению с двумя предыдущими случаями, он в общем случае небезопасен. В этом случае возникновение ситуации, когда модифицируемое поле окажется измененным другим пользователем, никак не контролируется, что может привести к непредсказуемым результатам при многопользовательском редактировании данных. Поэтому применение значения UpWhereKeyOnly допустимо только в том случае, когда вероятность одновременной модификации одной и той же записи несколькими пользователями крайне мала.
Повышение эффективности SQL-запросов
Эффективное программирование на SQL — тема весьма обширная, достойная отдельной статьи (и даже не одной). Возможность и результативность использования многих приемов оптимизации нередко зависит от особенностей используемого сервера баз данных и управляющей его работой операционной системы. Поэтому здесь мы лишь кратко перечислим наиболее часто употребляемые приемы оптимизации SQL-предложений.
Если требуется определить наличие в таблице записей, удовлетворяющих какому-либо условию, следует предпочесть использование предиката EXIST запросу, вычисляющему число таких записей. Запрос вида
SELECT * FROM <имя таблицы> WHERE (SELECT COUNT (*) FROM <имя
таблицы> WHERE <условие>) >0
заставит сервер при выполнении внутреннего подзапроса перебрать все
строки таблицы, проверяя соответствие каждой записи указанному условию,
тогда как запрос вида
SELECT * FROM <имя таблицы> WHERE EXISTS (SELECT * FROM <имя
таблицы> WHERE <условие>)
заставит сервер перебирать записи до нахождения первой записи, удовлетворяющей
указанному условию. Лишний перебор записей на сервере, естественно,
занимает некоторое время — чудес не бывает.
Многие приемы оптимизации связаны с использованием индексов. Если какое-либо поле таблицы часто используется в предложении WHERE, сравнивающем его значение с какой-либо константой или параметром, наличие индекса для этого поля ускоряет подобные операции. По этой же причине рекомендуется индексировать внешние ключи у таблиц с большим числом записей. Однако следует иметь в виду, что поддержка индексов замедляет операции вставки записей, поэтому при проектировании данных следует взвесить все "за" и "против" создания индексов, а еще лучше — провести соответствующее тестирование, заполнив таблицы случайными данными (для этой цели можно написать соответствующее приложение, а еще лучше — воспользоваться готовыми средствами тестирования типа SQA Suite).
Говоря об использовании индексов, следует также обратить внимание на то, что при использовании индексированных полей в качестве аргументов функций наличие индекса не влияет на скорость выполнения запроса — индекс в этом случае не используется.
Особо следует отметить проблемы, связанные с использованием вложенных запросов. Дело в том, что скорость выполнения запроса существенно зависит от числа уровней вложенности подзапросов (время выполнения примерно пропорционально произведению числа записей в таблицах, используемых в подзапросах). Фактически проверка соответствия условию WHERE каждой записи из внешнего подзапроса инициирует выполнение внутреннего подзапроса, что особенно заметно сказывается при большом числе записей. В практике автора чуть более года назад был случай, когда при приведении в порядок одной из используемых корпоративных информационных систем после выполнения нескольких обычных запросов на обновление данных в таблице с несколькими десятками тысяч записей, выполнявшихся в течение нескольких секунд, был инициирован вложенный запрос на обновление данных к этой же таблице. Этот запрос выполнялся более двух часов (чего, вообще говоря, и следовало ожидать). Поэтому использовать вложенные запросы следует только в тех случаях, когда без них нельзя обойтись. Альтернативой использования вложенных запросов может служить фильтрация результатов обычного запроса в клиентском приложении либо последовательное выполнение нескольких запросов с созданием временных таблиц на сервере.
Оптимизация клиентского приложения
Методы оптимизации клиентского приложения мало чем отличаются от методов оптимизации обычных приложений C++Builder. Обычно оптимизация заключается в повышении быстродействия приложения и в снижении объема используемых ресурсов операционной системы.
Снижение количества потребляемых ресурсов возможно разными способами. Основной принцип их экономии — не использовать ресурсы впустую. Именно поэтому рекомендуется в приложениях, использующих большое количество форм, создавать их динамически и уничтожать, как только они становятся ненужными (что отличается от установок менеджера проектов по умолчанию, которые предполагают автоматическое создание всех форм сразу же). Однако при этом следует помнить, что модуль данных, содержащий компоненты доступа к данным, используемые интерфейсными элементами динамически создаваемой формы, должен быть создан до создания самой формы, дабы избежать исключительной ситуации, связанной с обращением к несуществующему объекту.
Избегать лишних связей с сервером следует не только из-за лишней перегрузки сети и сервера, но и из-за того, что они поглощают некоторое количество ресурсов и замедляют работу приложения.
Еще одним способом экономии ресурсов клиентского приложения является использование более экономичных интерфейсных элементов в случаях, где это возможно (например, TDBText или TLabel вместо TDBEdit, TLabel вместо TDBMemo при отображении полей, редактирование которых не предполагается, TDBGrid вместо TDBControlGrid и т.д.).
Еще один прием, повышающий быстродействие клиентского приложения, заключается в сокращении числа операций, связанных с выводом данных из таблиц на экран, например, при "пролистывании" большого количества строк в компонентах типа TDBGrid или TDBCtrlGrid в процессе навигации по набору данных или какой-либо их обработки. В этом случае рекомендуется на время отключать связь интерфейсных элементов с компонентом TDataSource, установив значение его свойства Enabled равным false (пример использования этого приема будет приведен ниже).
О навигационных методах и "клипперном" стиле програмирования
Говоря об оптимизации клиент-серверных информационных систем, хотелось бы отдельно остановиться на одной очень распространенной ошибке, совершаемой программистами, имеющими большой опыт работы с настольными СУБД и средствами разработки, базирующимися на xBase-языках, такими, как Clipper, dBase, FoxPro и др. При использовании средств разработки такого рода какое-либо изменение данных в таблице согласно каким-либо правилам осуществляется обычно путем создания цикла типа:
USE HOLDINGS
GO TOP
DO WHILE !EOF()
PUR_PRICE=PUR_PRICE+10
SKIP
ENDDO
CLOSE
В приведенном фрагменте xBase-кода PUR_PRICE — имя поля таблицы HOLDINGS, подверженного изменению.
При переходе к архитектуре клиент/сервер и средствам разработки, поддерживающим SQL, поначалу возникает естественное желание продолжать писать подобный код, используя циклы и навигацию по таблице. Это не так страшно в случае использования C++Builder с настольными СУБД — локальный SQL, способный быть альтернативой в этом случае, в конечном итоге также инициирует перебор записей таблицы. Вообще говоря, то же самое происходит и при выполнении запроса типа UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE+10 на сервере баз данных, но подобный цикл является внутренним процессом сервера, в котором не задействованы ни клиент, ни сеть. Однако при использовании "клипперного" стиля программирования библиотека BDE вовсе не обязана догадываться, что имел в виду программист, написавший подобный цикл, и генерирует вовсе не такие запросы!
Рассмотрим простой пример. Создадим копию таблицы HOLDINGS.DBF из входящей в комплект поставки C++Builder базы данных DBDEMOS на каком-либо сервере баз данных, например, Personal Oracle (воспользовавшись, например, утилитой Data Migration Wizard из комплекта поставки Borland C++Builder). Затем создадим новое приложение, состоящее из одной формы, включающей компоненты TDBGrid, TTable, TDataSource, TQuery, TDBNavigator и три кнопки (рис.3).
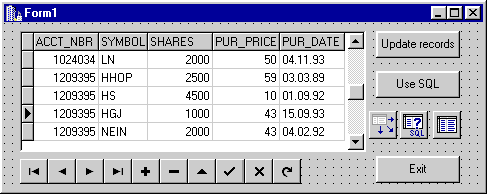
Рис.3. Главная форма приложения для тестирования SQL-запросов, генерируемых BDE
Установим следующие значения свойств используемых компонентов (табл.1):
Таблица 1.
| Компонент | Свойство | Значение |
|---|---|---|
| DBNavigator1 | DataSource | DataSource1 |
| DBGrid | DataSource | DataSource1 |
| Button1 | Caption | 'Use SQL' |
| Button2: | Caption | 'Update records' |
| Button3: | Caption | 'Exit' |
| DataSource1 | DataSet | Table1 |
| Table1 | DatabaseName | ORACLE7 |
| TableName | HOLDINGS | |
| UpdateMode | UpWhereKeyOnly | |
| Table1PUR_PRICE | FieldName | 'PUR_PRICE' |
| Query1 | DatabaseName | ORACLE7 |
| SQL | 'UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE+10' |
Теперь создадим обработчики событий, связанные с нажатием на кнопки. Кнопка Update records реализует аналог фрагмента xBase-кода, приведенного выше:
void __fastcall TForm1::Button2Click(TObject *Sender)
{
Table1->First();
DataSource1->Enabled=false; //Не будем издеваться над видеоадаптером!
while (!Table1->Eof)
{
Table1->Edit();
Table1PUR_PRICE->Value=Table1PUR_PRICE->Value+10;
Table1->Next();
}
DataSource1->Enabled=true; //Посмотрим, что получилось...
}
Временное отключение связи между DataSource1 и Table1 в данном обработчике событий сделано для того, чтобы исключить перерисовку компонента DBGrid1 при изменении каждой записи.
Кнопка Use SQL реализует выполнение одиночного SQL-запроса UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE+10:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
Query1->Prepare();
Query1->ExecSQL();
Table1->Refresh(); //Посмотрим на результат...
}
Скомпилировав приложение, запустим SQL Monitor и посмотрим, какие запросы генерируются BDE при нажатии на эти кнопки.
При использовании кнопки Update records log-файл имеет следующий вид:
- 14:37:08 SQL Prepare: ORACLE — UPDATE "HOLDINGS" SET "PUR_PRICE"=:1 WHERE "ROWID"=:2
- 14:37:08 SQL Execute: ORACLE — UPDATE "HOLDINGS" SET "PUR_PRICE"=:1 WHERE "ROWID"=:2
- 14:37:08 SQL Stmt: ORACLE — Close
- 14:37:08 SQL Prepare: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:37:08 SQL Execute: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:37:08 SQL Misc: ORACLE — Set rowset size
- 14:37:08 SQL Stmt: ORACLE — Fetch
- 14:37:08 SQL Stmt: ORACLE — EOF
- 14:37:08 SQL Stmt: ORACLE — Close
- 14:37:08 SQL Prepare: ORACLE — UPDATE "HOLDINGS" SET "PUR_PRICE"=:1 WHERE "ROWID"=:2
И так далее, пока не кончатся все записи…
- 14:37:10 SQL Prepare: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:37:10 SQL Execute: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:37:10 SQL Misc: ORACLE — Set rowset size
- 14:37:10 SQL Stmt: ORACLE — Fetch
- 14:37:10 SQL Stmt: ORACLE — EOF
- 14:37:10 SQL Stmt: ORACLE — Close
Отметим, что это еще не самый большой набор запросов для данного случая, так как при обновлении таблицы было использовано значение UpWhereKeyOnly свойства UpdateMode компонента Table1, при котором запросы на обновление одной записи имеют минимальный набор проверяемых параметров.
При использовании кнопки Use SQL log-файл имеет совершенно другой вид:
- 14:35:51 SQL Prepare: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10
- 14:35:51 SQL Transact: ORACLE — Set autocommit on/off
- 14:35:51 SQL Execute: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10 14:35:51 SQL Stmt: ORACLE — Close
Остальные SQL-запросы, содержащиеся в log-файле, генерируются BDE при выполнении метода Refresh() компонента Table1:
- 14:35:51 SQL Prepare: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:35:51 SQL Execute: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE "ACCT_NBR"=:1
- 14:35:51 SQL Misc: ORACLE — Set rowset size
- 14:35:51 SQL Stmt: ORACLE — Fetch
- 14:35:51 SQL Stmt: ORACLE — EOF
- 14:35:51 SQL Stmt: ORACLE — Close
- 14:35:51 SQL Prepare: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE (("ACCT_NBR" IS NULL OR "ACCT_NBR"> :1)) ORDER BY "ACCT_NBR" ASC
- 14:35:51 SQL Execute: ORACLE — SELECT "ACCT_NBR" ,"SYMBOL" ,"SHARES" ,"PUR_PRICE" ,"PUR_DATE" ,"ROWID" FROM "HOLDINGS" WHERE (("ACCT_NBR" IS NULL OR "ACCT_NBR"> :1)) ORDER BY "ACCT_NBR" ASC
- 14:35:51 SQL Misc: ORACLE — Set rowset size
- 14:35:51 SQL Stmt: ORACLE — Fetch
Если из текста обработчика события Button1Click удалить строку
Table1->Refresh();,
то действия с 5-го по 14-е выполняться не будут. Кроме того, при нажатии на эту же кнопку несколько раз подряд log-файл будет иметь следующий вид:
- 14:11:36 SQL Prepare: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10
- 14:11:36 SQL Execute: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10
- 14:11:40 SQL Stmt: ORACLE — Reset
- 14:11:40 SQL Execute: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10
- 14:14:17 SQL Stmt: ORACLE — Reset
- 14:14:17 SQL Execute: ORACLE — UPDATE HOLDINGS SET PUR_PRICE=PUR_PRICE-10
- 14:14:19 SQL Stmt: ORACLE — Reset
Как видим, компиляция запроса сервером осуществляется в этом случае только один раз.
Итак, мы видим, что "клипперный" стиль программирования при работе с SQL-серверами абсолютно неприемлем — он приводит к перегрузкам сервера, сети и рабочей станции одновременно, а разница в скорости выполнения заметна даже при небольшом объеме таблицы и использовании локального сервера, поэтому, анализируя причины низкой производительности приложений, стоит посмотреть — а нет ли в клиентском приложении подобных фрагментов кода?
В заключение хотелось бы отметить, что оптимизация клиент-серверных информационных систем должна производиться с учетом результатов анализа производительности и тщательного тестирования, возможно, не только с помощью SQL Monitor, но и с помощью специальных средств тестирования, обладающих дополнительными функциональными возможностями.