| klen |
| Отправлено: 13.01.2006, 11:45 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239

|
Здравствуйте друзья.
Вчера преобрел двухядерный проц Athlon64 X2 4400+.
Для определения зря или не зря потрачено 15 килорублей написал маленький тестовый пример расчета косинусного интеграла Френеля, в котором в зависимости от указанного в командной строке числового параметра вычисления разносятся на это число потоков.
В итоге получено при 2 и более потоках повышение скорости в 2!!! раза с точностью до велечины блиской к нулю.
Вывод: коллеги, у кого иеется специфика написания вычислительных задач позволяющих распаралелить вычисления (нпример расчет интегральных функций или решение систем диффур или просто независимая логика работы модулей) то выполчите реально +2 раза скорости. Раньше меня пугали что компиллер дескать должен быть оптимизирующий под многопроцессорную архитектуру, еще всяко охинею несли... а я слушал и сомневался от незнания. Оптимизирущим должен быть программер а не компиллер!
Здесь выложил исходники и бинарник этого тестика с результатами на моей машинке. Можете глянуть как это работает и попробывать переписать такимже макаром свои модули требующие оптимизации.
http://www.klen.org/Projects/TestCpu/testcpu.html
|
|
| olegenty |
| Отправлено: 13.01.2006, 12:00 |
|
Ветеран
Группа: Модератор
Сообщений: 2412
|
пустую страницу вижу при переходе по ссылке...
|
|
| avc* |
| Отправлено: 13.01.2006, 12:24 |
|
Не зарегистрирован
|
А у меня не пустая. 
В какой ОС это происходило? |
|
| klen |
| Отправлено: 13.01.2006, 12:47 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
2_olegenty
Я в HTML кодировании как свиння в апельсинах разбираюсь, зато имею долгий опыт с Flash, поэтому весь свой сайт захерачен на Flash (на нем в отлии от других вариантов можно ПРОГРАММЫ ПИСАТЬ!). У вас модет плагина к броузеру не стоит или выключен он или прокси не пускает файлы с расширением *.swf
Выкачать можно так
http://www.klen.org/Projects/TestCpu/TestCpu.rar
http://www.klen.org/Projects/TestCpu/TestCpuSrc.rar
2_avc
Я использую W2k c последними обновлениями. Я старался такой объем данных использовать чтоб все в кэш вмещалось и скорость работы памяти не влияла на результаты. |
|
| Konstantine |
| Отправлено: 13.01.2006, 16:32 |
|
Мастер участка
Группа: Модератор
Сообщений: 545
|
меня идея заинтересовала и решил проверить на своём компе (P-3000HT)
ну 10 экспериментов проводить влом — провёл по одному, и результат тоже впечатлил — 28328 (1 поток) против 18250 (2 потока) т.е. Hyper Threading тоже даёт немалый эффект (не в 2 раза конечно, но и полтора тоже хорошо)
|
|
| klen |
| Отправлено: 13.01.2006, 17:39 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
Вывод един — КОШЕК НАДА УМЕТЬ ГОТОВИТЬ!
Яраньше никогда потоками не пренебрегал — применял когда это удобно, например когда используешь блокирующие вызовы. А теперь другое дело — не только удобство но и эффективность.
Всетаки это загадка, как пишут "друзья" в больших компаниях свой высокотехнологичный софт?
Ну там архиваторы, кодеки, рендеры, и куча всего остального. Посмотрите на тести — особой разницы нет c HT и c DualCore.
Сидят там студенты и линкую библиотеки содержащие код который еще дедушки писан под 386 машины для доса?
Во сижу щас и читаю статью UPGRADE #1 январь, статья "2006 причин прочитать даный текст" в которой тов. Сергей Бучин распинается что двухпроцессорные машинки — это типа кризис жанра!! Видители интел и амд в тупик зашли и чтоб хоть чтото было вынуждены делать два ядра.
Вобщем этот глупый "железный редактор" UPGRAD'а нихера не соображает что это не производители железа в тупик зашли а кривописатели выполняемого на них кода!
Отредактировано klen — 13/01/2006, 17:49 |
|
| -=\SeaWolF/=- |
 Отправлено: 14.01.2006, 15:07 Отправлено: 14.01.2006, 15:07 |
|

Ученик-кочегар
Группа: Участник
Сообщений: 24
|
Гм... интересно... интересно... А вот как оно интересно обстоит с интел технологией HT — этож вроде бы виртуальный второй процессор...
Хотя лубоко лазить не интересно....
Ответит кто ... на такой вопрос...
В чем отличия например Интеловкой и Амдешной многоядерностью
В чем сходства и отличия....
Мне вот до сих пор не понятно с чем кушать HT польза есть от него или нету.... или опять все дело в коде (многопоточные вычисления)....?
PS добавил после проверки....
Вот программер хацкер....
Это же надо так код написать...
10 — 21109 mc
5 — 21984 mc
2 — 21297 mc
1 — 36515 mc
Гм интересно... но опять встает вопрос о том как определять использовать тот или иной алгоритм расчета... 
И видимо придется лазить в асемблер и определять что за процессор...
(хотя я видимо опять живу в каменном веке)
И судя по тесту потоков должно ббыть не более чем самих процессоров
иначе эфект быстродействия снижается... ( а жаль
Отредактировано -=\SeaWolF/=- — 14/01/2006, 15:27 |
|
| klen |
| Отправлено: 14.01.2006, 23:30 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
| QUOTE (-=\SeaWolF/=- @ 14/01/2006, 15:07) |
Ответит кто ... на такой вопрос...
В чем отличия например Интеловкой и Амдешной многоядерностью
В чем сходства и отличия....
Мне вот до сих пор не понятно с чем кушать HT польза есть от него или нету.... или опять все дело в коде (многопоточные вычисления)....?
PS добавил после проверки....
Вот программер хацкер....
Это же надо так код написать...
10 — 21109 mc
5 — 21984 mc
2 — 21297 mc
1 — 36515 mc
Гм интересно... но опять встает вопрос о том как определять использовать тот или иной алгоритм расчета...
И видимо придется лазить в асемблер и определять что за процессор...
(хотя я видимо опять живу в каменном веке)
И судя по тесту потоков должно ббыть не более чем самих процессоров
иначе эфект быстродействия снижается... ( а жаль |
| QUOTE |
Гм... интересно... интересно... А вот как оно интересно обстоит с интел технологией HT — этож вроде бы виртуальный второй процессор...
Хотя лубоко лазить не интересно.... |
Наверно нада это так понитмать — в каждом потоке (как в моем тесте) есть участки кода выполняющегося на СPU и FPU, пока одна нить например адреса вычисляет пока не дойдет до инструкции с плавающей запятой, другая выполняет инструкции с плавающей запятой пока не дойдет до инстркуции CPU , а устройство управления процессора согласно заданной стратегии выдает ждущему потоку CPU или FPU если он простаивает. Примерно так, только сложнее, потому чьто еще расшариваются модули типа адрессных сумматоров, модулей сдвига CPU, и тд. Я лично так понимаю HT. А у атлонов x2 просто честное разделение потоков по ядрам.
| QUOTE |
Гм интересно... но опять встает вопрос о том как определять использовать тот или иной алгоритм расчета...
И видимо придется лазить в асемблер и определять что за процессор...
(хотя я видимо опять живу в каменном веке). |
Тебя в этом случае спасет API GetProcessAffinityMask — она укажет скоко програмно доступных (не обящательно реальных — как например HT процессоров(ядер)) доступно для исполнения потоков. А дальше сам решашай как потоки распределить по процессорам — твоя воля SetThreadAffinityMask.
Можно прочитать реестр HKLM\HARDWARE\DESCRIPTION\System\CentralProcessor — это факультативно.
Я щас пишу компонент который будет распаралеливать вычисления . Eсли кому будет интересно могу выложить.
Отредактировано klen — 14/01/2006, 23:33 |
|
| Георгий |
| Отправлено: 15.01.2006, 04:59 |
|
Почетный железнодорожник
Группа: Модератор
Сообщений: 874
|
прикольно
у меня на однопроцессорном AMD barton 2500+
1-4 потока время ~23 000 ms
25 19 800 ms
50 время 16 200 ms (т.е. на 30% меньше чем с 1 потоком)
75 программа завершилась до того, как все потоки отработали (видно в task manager) и написала, что она работала 0 ms — явный глюк
Отредактировано Георгий — 15/01/2006, 06:16 |
|
| klen |
| Отправлено: 15.01.2006, 11:39 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
| QUOTE | прикольно
у меня на однопроцессорном AMD barton 2500+
1-4 потока время ~23 000 ms
25 19 800 ms
50 время 16 200 ms (т.е. на 30% меньше чем с 1 потоком) |
Это все происки планировщика, он у микрософта иногда бывает "очарован" чем то. Поэтому иногда удивительные вещи бывают, такая хитро-жопо-вытесняющая многозадачность. На линухе все более менее "ровно" происходит, потому что по своей природе ядро линуха никогда по "своей инициативе" ничего не делает, только если четко об этом попросить.
| QUOTE |
75 программа завершилась до того, как все потоки отработали (видно в task manager) и написала, что она работала 0 ms — явный глюк |
Гдето чето не так пошло... бывает.
|
|
| Георгий |
| Отправлено: 15.01.2006, 13:14 |
|
Почетный железнодорожник
Группа: Модератор
Сообщений: 874
|
а вычислительный алгоритм, когда распределяет вычисления по потокам, не может делать где-нибудь допущения/упрощения приводящие к потере вычислительных циклов ?
я с косинусным интегралом Френеля не знаком и могу только предполагать — может на граничных условиях что-то не так? а то 30% скачёк при увеличении числа потоков настораживает.
а планировщик винды очень напоминает не приоритетную систему, а систему массового обслуживания и к приоритетам потоков и прочим вещам относится как к рекомендациям, а не указаниям.
Отредактировано Георгий — 15/01/2006, 14:14 |
|
| klen |
| Отправлено: 15.01.2006, 16:06 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
| QUOTE (Георгий @ 15/01/2006, 13:14) | а вычислительный алгоритм, когда распределяет вычисления по потокам, не может делать где-нибудь допущения/упрощения приводящие к потере вычислительных циклов ?
|
Неа не может, тамже исходник выложен. Спецально чтоб ко мне вопросов не было что я жульничую.
Все потоки работают по одному алгоритму, только данные разные над которыми выполнена операция. Простой пример с вычислением суммы ряда до 10 члена: все потоки вычислютя член и складывают его с суммой, только 1 поток работает номерами членов от 1 до 5 а второй например от 5 до 10, поэтому и скорость получается выше.
а ваши 30% полученны именно так как вы сказали — "виндовс принимает к сведению..."
Отредактировано klen — 15/01/2006, 16:07 |
|
| -=\SeaWolF/=- |
| Отправлено: 15.01.2006, 21:42 |
|
Ученик-кочегар
Группа: Участник
Сообщений: 24
|
| QUOTE |
Я щас пишу компонент который будет распаралеливать вычисления . Eсли кому будет интересно могу выложить. |
Жуть как интересно! было бы здорово..... 
Отредактировано -=\SeaWolF/=- — 15/01/2006, 21:44 |
|
| klen |
| Отправлено: 16.01.2006, 13:16 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
Компанент готов, тока пока подглюкиват, ка глюки вылижу выложу с примером:
на форме рисуется вычисляемая функция и указывается время вычислений.
А вобщем второе ядро добавило к моей "PC програмной" жизни новый оттенок и запах! Интересно блин. Вот бы еще гденить 8 процессорную машинку найти.. |
|
| klen |
| Отправлено: 16.01.2006, 13:21 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
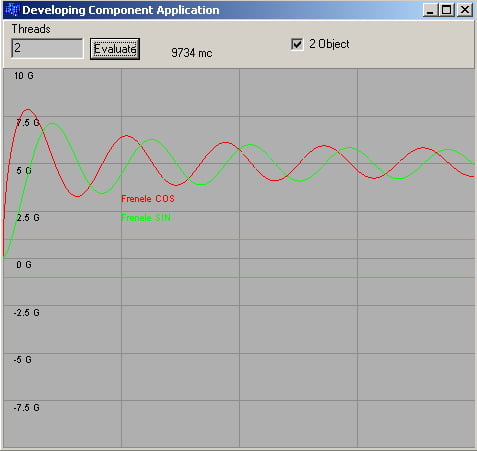
Вот скрин примерчика
Присоединить изображение
|
|
| -=\SeaWolF/=- |
| Отправлено: 18.01.2006, 19:36 |
|
Ученик-кочегар
Группа: Участник
Сообщений: 24
|
У меня впринципе возникла мысль....
что объединив машины в кластеры (сервера)
можно использовать распределенные вычисления....
видимо что-то подобное используется уже....
но... думаю что и твоим модуям можно в примитиве придать тоже применение..... но думаю твоя идея воплотима еще более на более высоком уровне..... |
|
| klen |
| Отправлено: 19.01.2006, 16:36 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
| QUOTE (-=\SeaWolF/=- @ 18/01/2006, 19:36) | У меня впринципе возникла мысль....
что объединив машины в кластеры (сервера)
можно использовать распределенные вычисления.... |
Под линуксом уже все давно есть — делаешь сеть из машин, ставиш софт-"сервера вычислений" а на одну машину клиентское ПО с средствами визаулизации результатов и средсвами управления. Все так и делают кому нада дохрена считать. Софт доступен. Есть даже российский пакет для этого, не помню в каком московском унивеситете написали.
Я же хочу именно для форточек сделать и именно для много ядерных процов — тут пустота, на одной машине раньше никто сербезно не считал, а щас PC сделают средненький мегакластер 10 летней давности . К тому же я сам постоянно расчетные задачи пишу, лучше 30 минут ждать чем 1 час.
Компанент написан и работает, напишу доку и примеры — выложу.
|
|
| klen |
| Отправлено: 22.01.2006, 22:46 |
|
Машинист паровоза
Группа: Участник
Сообщений: 239
|
библиотека с компаентом который распараллеливат вычисления функций с докой и примерами выложены, если кому интересно и будут проблемы — сообщайте.
http://www.klen.org/Projects/KlenVCLCompon...lenmathlib.html
|
|
| -=\SeaWolF/=- |
| Отправлено: 24.01.2006, 04:58 |
|
Ученик-кочегар
Группа: Участник
Сообщений: 24
|
2klen сипасибо пока только что скачал...
как появится время попробую разобрать и куданить притулить и посмотерь что из этого вообще у меня выйдет |
|